
If you are unfamiliar with the basics of neural networks and back-propagation in neural networks, I recommend checking the below articles. These articles increase your confidence while reading this article. You can find all mathematical basic concepts about feed-forward neural networks in these articles.

Before we start our journey 🚀 let’s find what are the properties of the activation function are necessary to become a good activation function?
Characteristics
Nonlinear:When the activation function is non-linear, then a two-layer neural network can be proven to be a universal function approximator
a universal function is a computable function capable of calculating any other computable function
If we use Linear functions throughout in network then the network is the same as perceptron (single layer network)
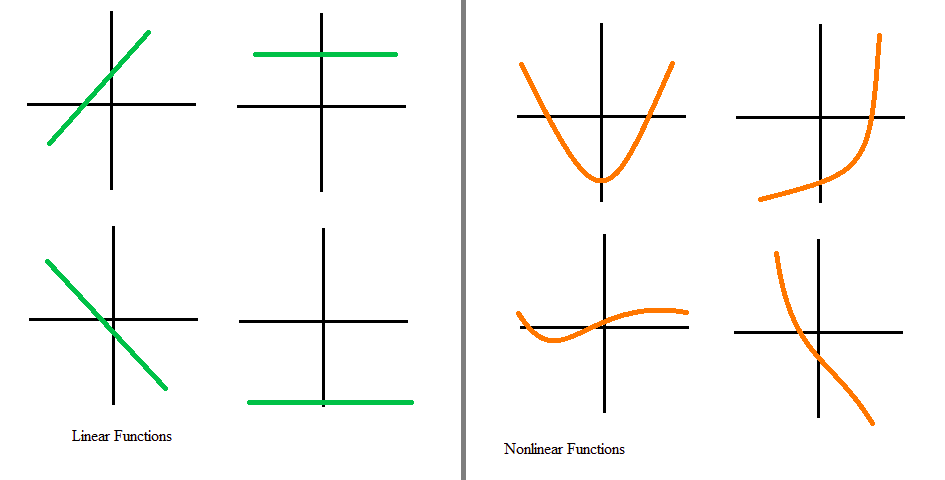
Range:When the range is finite, gradient-based optimization methods are more stable because it limits the weights. When the range is infinite, gradient-based optimization methods are more efficient but for smaller learning rates. because weights updation doesn't have a limit on the activation function. You can refer to \(1^{st}\) article in the above list. You will find, weight updation is dependent on the activation function also.
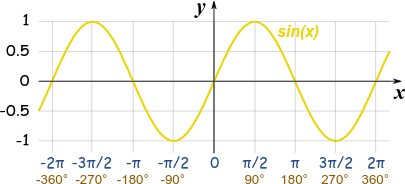
Range and Domain: The domain of a function \(f(x)\) is the set of all values for which the function is defined, and the range of the function is the set of all values that \(f\) takes.
For example take function \(f(x)=\sin{(x)}\) which is sine function. Its range is \([-1,1]\) and domain is \((-\infty,+\infty)\)
Continuously differentiable:A continuously differentiable function \(f(x)\) is a function whose derivative function \(f'(x)\) is also continuous in it's domain. I recommend to check Youtube: Continuity Basic Introduction, Point, Infinite, & Jump Discontinuity, Removable & Nonremovable
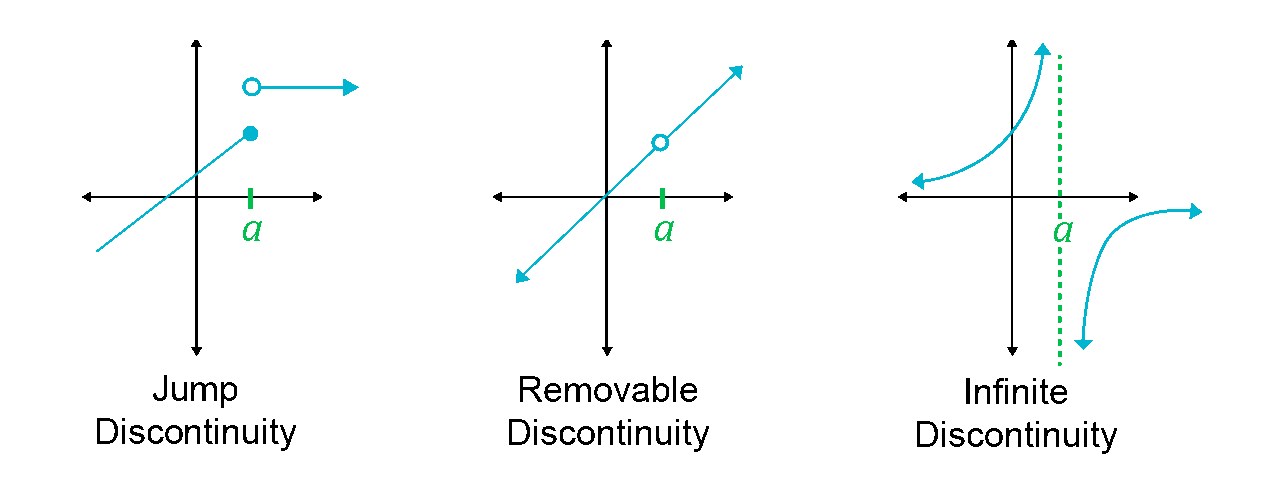
In the below image, the function is a binary step function and it is discontinuous at \(x=0\) and it is jump discontinuity. As it is not differentiable at \(x=0\), so gradient-based methods can make no progress with it.
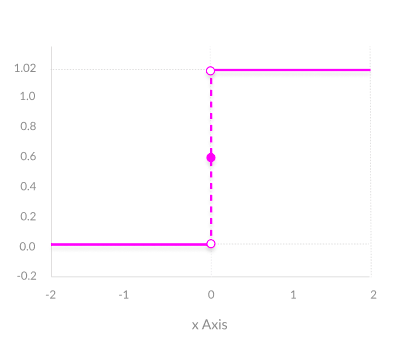
Monotonic:
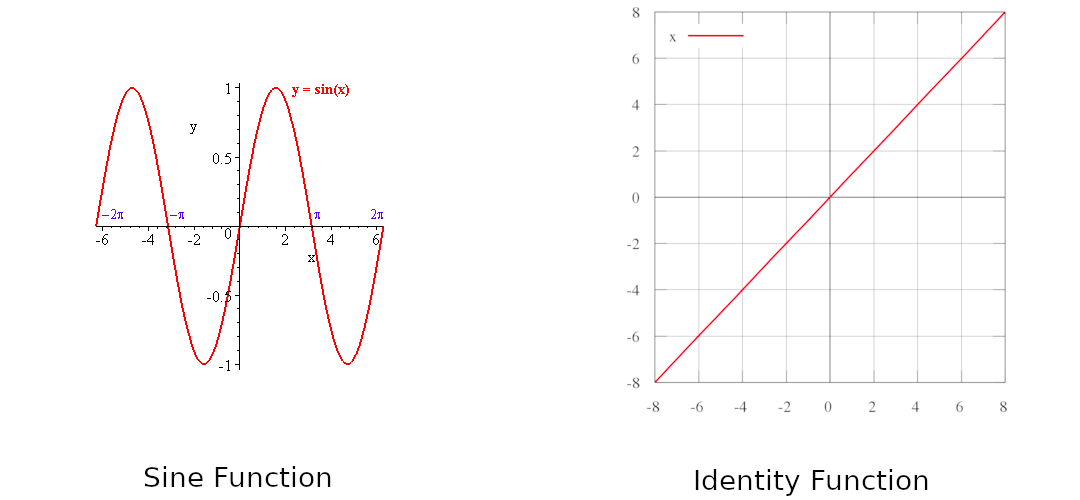
In calculus, a function \(f\) defined on a subset of the real numbers with real values is called monotonic if and only if it is either entirely non-increasing, or entirely non-decreasing.
Identity Function is monotonic function (\(f(x)=x\)) and \(f(x)=\sin{(x)}\) is non-monotonic function.
When the activation function is monotonic, the error surface associated with a single-layer model is guaranteed to be convex.
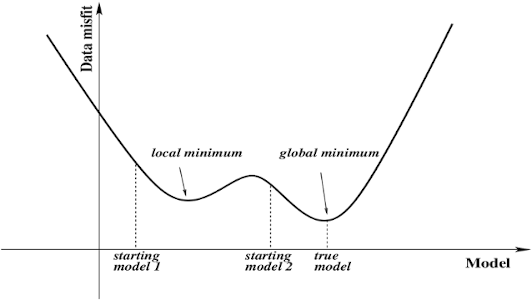
Monotonic Derivative:Smooth functions with a monotonic derivative have been shown to generalize better in some cases. I think it's because of the local minima problem. While training sometimes networks are stuck at local minima instead of global minima.
Approximates identity near the origin:Usually, the weights \(W\) and bias \(b\) are initialized with values close to zero by the gradient descent method. Consequently, \(WX^T + b\) or in our case \(WX + b\) (Check Above Series) will be close to zero.
If \(f\) approximates the identity function near zero, its gradient will be approximately equal to its input.
In other words, \(\partial{f} ≈ WX^T + b ⇐⇒ WX^T + b ≈ 0\). In terms of gradient descend, it is a strong gradient that helps the training algorithm to converge faster.
Activation Functions
From onward \(f(x)\) is equation of activation function and \(f'(x)\) is derivative of that activation function which is required during backpropagation. We will see the most used activation function and you can find others on Wikipedia page Link. All function graphs are taken from book named Guide to Convolutional Neural Networks: A Practical Application to Traffic-Sign Detection and Classification written by Aghdam, Hamed Habibi and Heravi, Elnaz Jahani
1. Sigmoid
\[
\begin{align*}
f(x) &= \frac{1}{1+e^{-x}} \\
f'(x) &= f(x)(1-f(x))
\end{align*}
\]
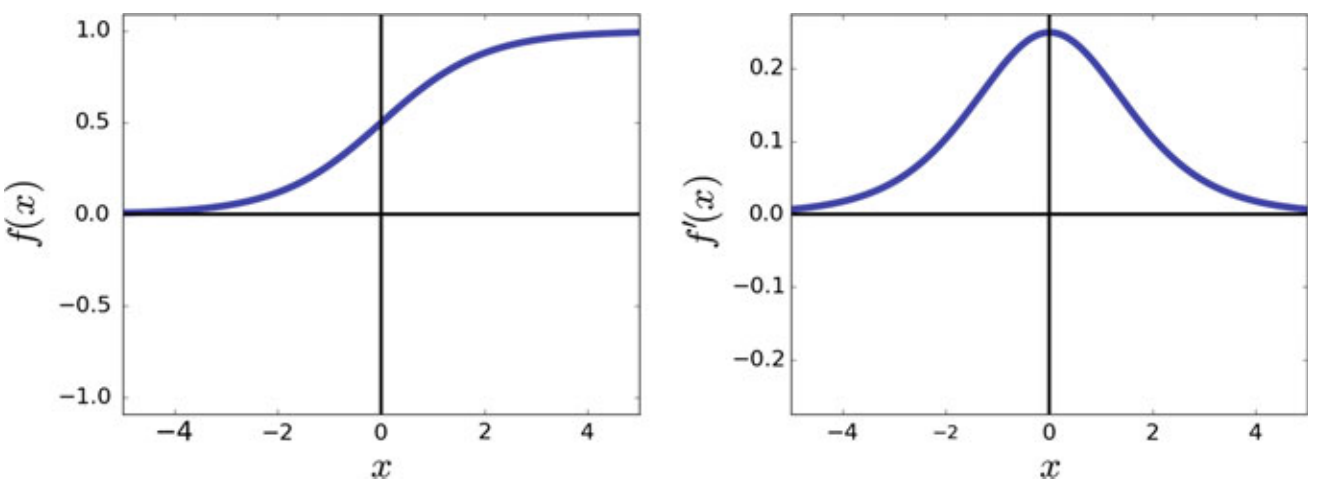
Pros:
- It is nonlinear, so it can be used to activate hidden layers in a neural network
- It is differentiable everywhere, so gradient-based backpropagation can be used with it
Cons:
- The gradient for inputs that are far from the origin is near zero, so gradient-based learning is slow for saturated neurons using sigmoid i.e. vanishing gradients problem
- When used as the final activation in a classifier, the sum of all classes doesn’t necessarily total 1
- For these reasons, the sigmoid activation function is not used in deep architectures since training the network become nearly impossible
Summary
| Range | \((0,1)\) |
|---|---|
| Order of Continuity | \(C^{\infty}\) |
| Monotonic | ✔ |
| Monotonic Derivative | ✖ |
| Approximates Identity near the origin | ✖ |
2. Hyperbolic Tangent
\[
\begin{align*}
f(x) &= \tanh{x} \\
&= \frac{e^{x} - e^{-x}}{e^{x}+e^{-x}} \\
f'(x) &= 1-(f(x))^2
\end{align*}
\]
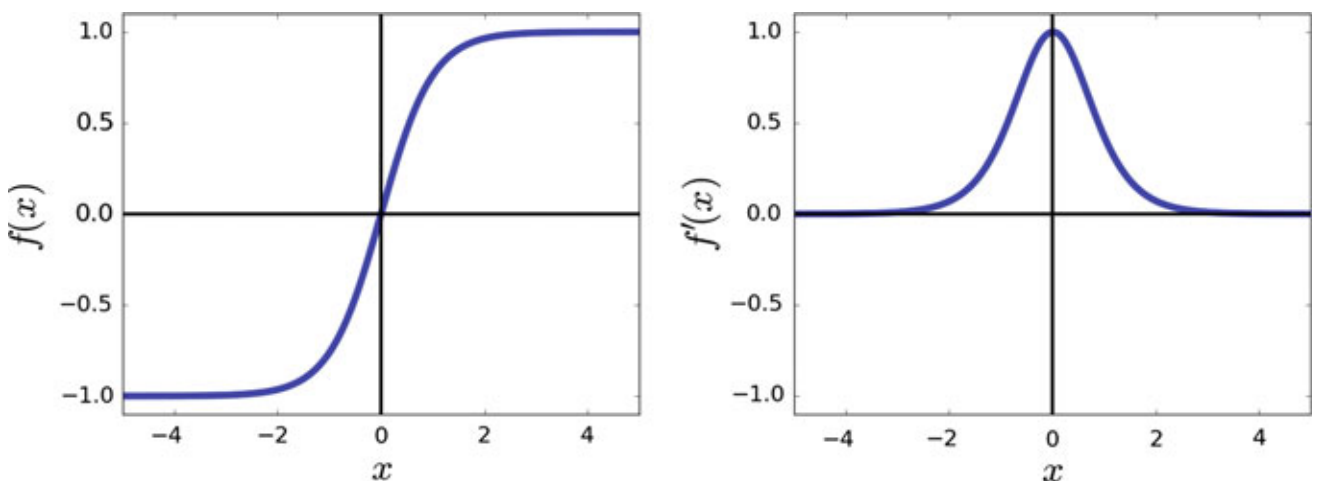
The hyperbolic tangent activation function is in fact a rescaled version of the sigmoid function.
Pros:
- It is nonlinear, so it can be used to activate hidden layers in a neural network
- It is differentiable everywhere, so gradient-based backpropagation can be used with it
- It is preferred over the sigmoid function because it approximates the identity function near the origin
Cons:
- As \(|x|\) increases, it may suffer from vanishing gradient problems like sigmoid.
- When used as the final activation in a classifier, the sum of all classes doesn’t necessarily total 1
Summary
| Range | \((-1,1)\) |
|---|---|
| Order of Continuity | \(C^{\infty}\) |
| Monotonic | ✔ |
| Monotonic Derivative | ✖ |
| Approximates Identity near the origin | ✔ |
3. Rectified Linear Unit
\[
\begin{align*}
f(x)&= max(0,x) \\
&=\begin{cases}
0, & \text{for } x\leq 0\\
x, & \text{for } x \gt 0
\end{cases} \\
f'(x) &= \begin{cases}
0, & \text{for } x\leq 0\\
1, & \text{for } x \gt 0
\end{cases}
\end{align*}
\]
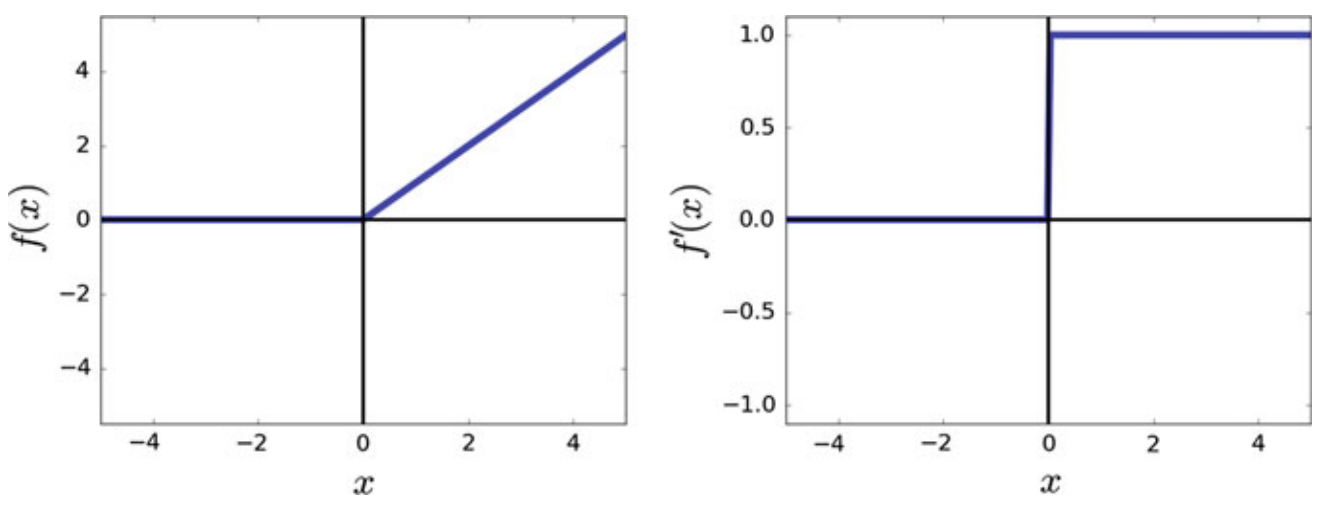
Pros:
- Computationally very efficient
- Its derivative in R+ is always 1 and it does not saturate in R+ (No vanishing gradient problem)
- Good choice for deep networks
- The problem of the dead neuron may affect learning but it makes it more efficient at the time of inference because we can remove these dead neurons.
Cons:
- The function does not approximate the identity function near the origin.
- It may produce dead neurons. A dead neuron always returns 0 for every sample in the dataset. This affects the accuracy of the model.
This happens because the weight of dead neuron have been adjusted such that \(WX^T + b\) for the neuron is always negative.
Summary
| Range | \([0,\infty)\) |
|---|---|
| Order of Continuity | \(C^{0}\) |
| Monotonic | ✔ |
| Monotonic Derivative | ✔ |
| Approximates Identity near the origin | ✖ |
4. Leaky Rectified Linear Unit
\[
\begin{align*}
f(x)&=
\begin{cases}
0.01x, & \text{for } x\leq 0\\
x, & \text{for } x \gt 0
\end{cases} \\
f'(x) &= \begin{cases}
0.01, & \text{for } x\leq 0\\
1, & \text{for } x \gt 0
\end{cases}
\end{align*}
\]
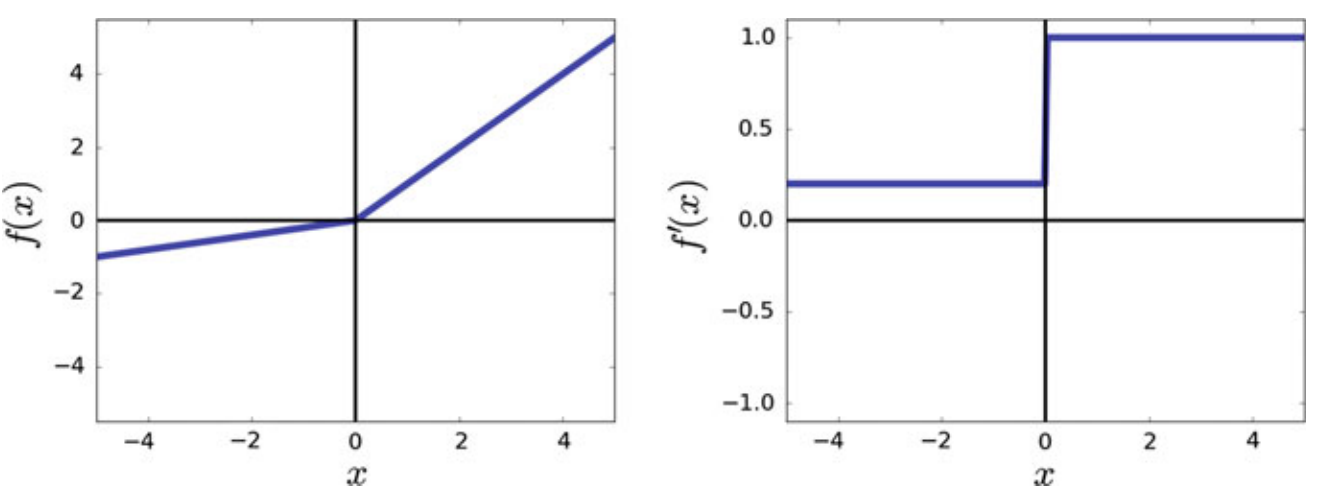
In practice, leaky ReLU and ReLU may produce similar results. This might be due to the fact that the positive region of these function is identical. 0.01 can be changed with other values between \([0,1]\)/
Pros:
- As its gradient does not vanish in negative region as opposed to ReLU, it solves the problem of dead neuron.
Cons:
Summary
| Range | \((-\infty,+\infty)\) |
|---|---|
| Order of Continuity | \(C^{\infty}\) |
| Monotonic | ✔ |
| Monotonic Derivative | ✔ |
| Approximates Identity near the origin | ✖ |
5. Parameterized Rectified Linear Unit
\[
\begin{align*}
f(x)&=
\begin{cases}
\alpha x, & \text{for } x\leq 0\\
x, & \text{for } x \gt 0
\end{cases} \\
f'(x) &= \begin{cases}
\alpha, & \text{for } x\leq 0\\
1, & \text{for } x \gt 0
\end{cases}
\end{align*}
\]
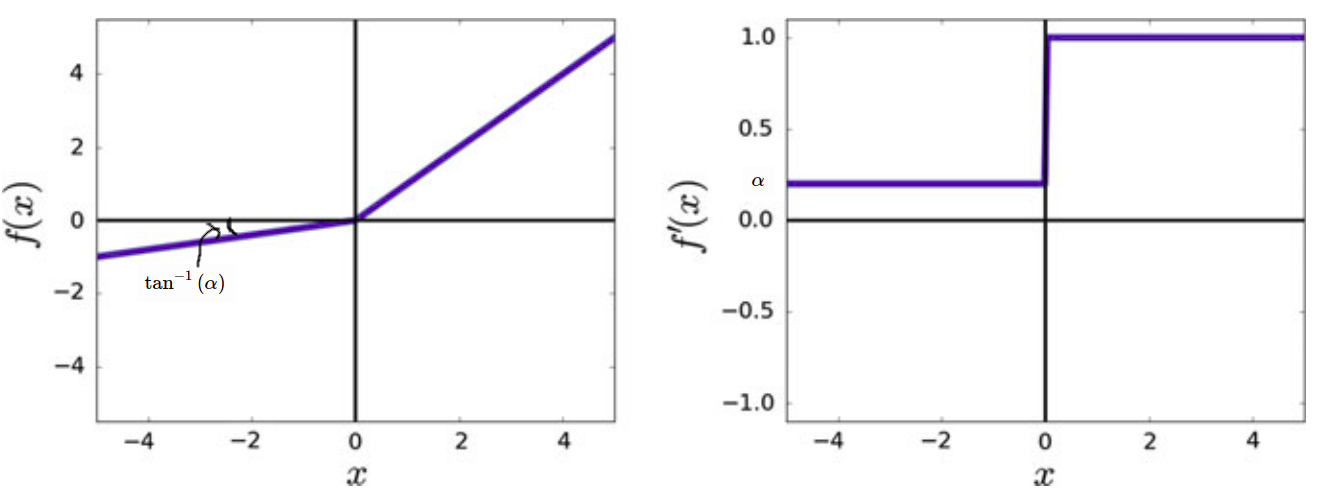
It is the same as Leaky ReLU but \(\alpha\) is a learnable parameter that can be learned from data.
Parameter Updation
To update \(\alpha\), we need gradient of activation function with respect to \(\alpha\).
\[
\begin{align*}
\partial{f(x)}&=
\begin{cases}
x, & \text{for } x\lt 0\\
\alpha, & \text{for } x \geq 0
\end{cases} \\
\end{align*}
\]
Summary
| Range | \((-\infty,+\infty)\) |
|---|---|
| Order of Continuity | \(C^{\infty}\) |
| Monotonic | ✔ |
| Monotonic Derivative | ✔ if \(\alpha \geq 0\) |
| Approximates Identity near the origin | ✔ if \(\alpha = 1\) |
6. Softsign
\[
\begin{align*}
Z^{[l]} &= W^{[l]}.a^{[l-1]} + b^{[l]} \\
a^{[l]} &= g^{[l]}{(Z^{[l]})}
\end{align*}
\]
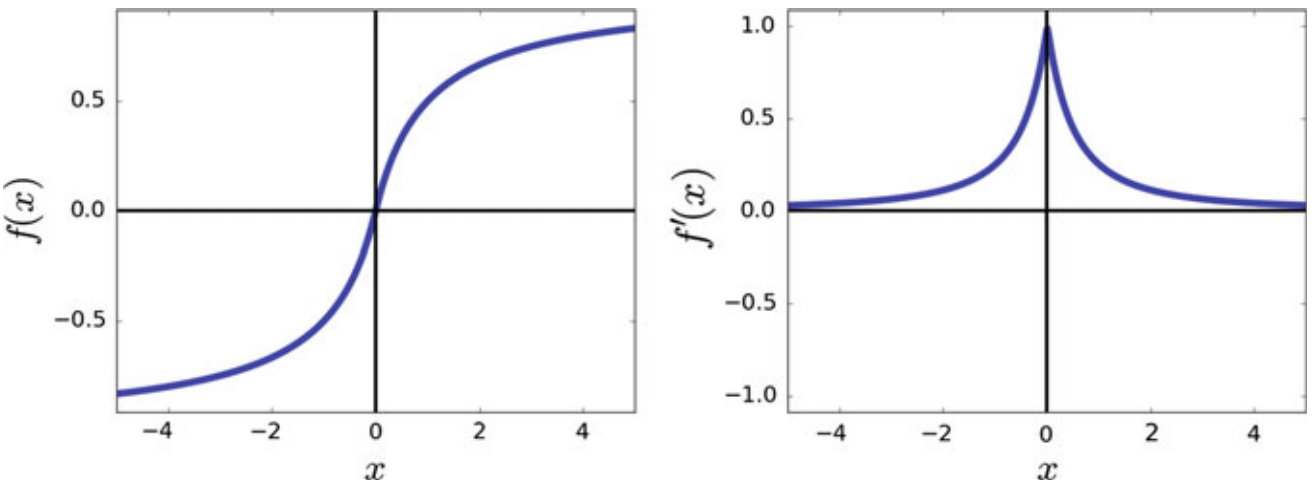
Pros:
- The function is equal to zero at origin and its derivative at origin is equal to 1. Therefore, it approximates the identity function at the origin.
- Comparing the function and its derivative with a hyperbolic tangent, we observe that it also saturates as \(|x|\) increases. However, the saturation ratio of the softsign function is less than the hyperbolic tangent function which is a desirable property
- the gradient of the softsign function near origin drops with a greater ratio compared with the hyperbolic tangent.
- In terms of computational complexity, softsign requires less computation than the hyperbolic tangent function.
Cons:
- saturates as \(|x|\) increases
Summary
| Range | \((-1,1)\) |
|---|---|
| Order of Continuity | \(C^{1}\) |
| Monotonic | ✔ |
| Monotonic Derivative | ✖ |
| Approximates Identity near the origin | ✔ |
7. Softplus
\[
\begin{align*}
f(x) &= \ln(1+e^x) \\
fi(x) &= \frac{1}{1+e^{-x}}
\end{align*}
\]
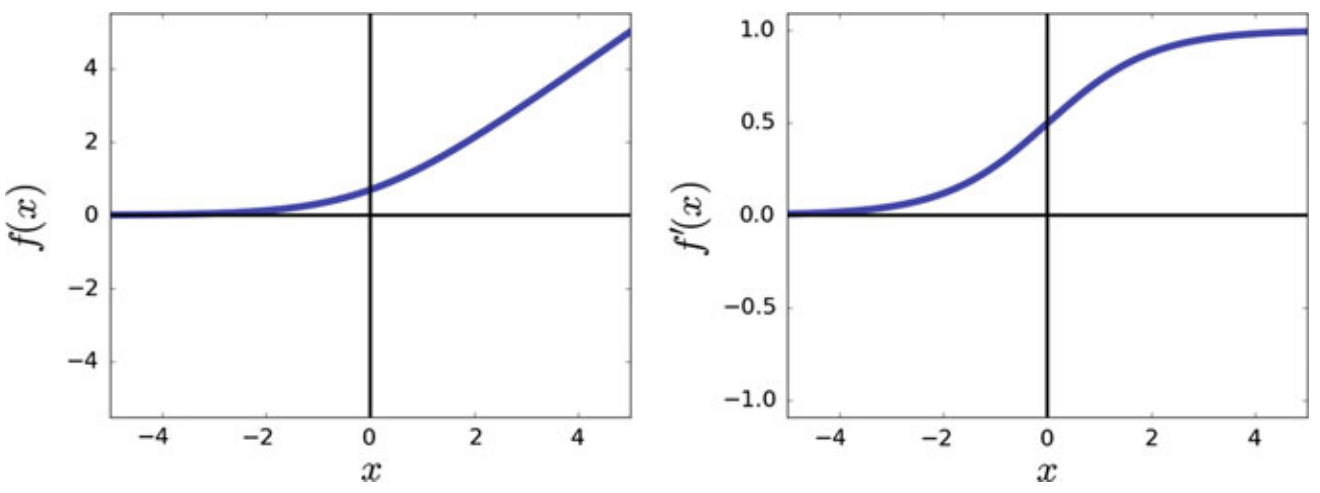
Pros:
- In contrast to the ReLU which is not differentiable at origin, the softplus function is differentiable everywhere
- The derivative of the softplus function is the sigmoid function which means the range of derivative is \([0,1]\)
Cons:
- the derivative of softplus is also a smooth function that saturates as \(|x|\) increases
Summary
| Range | \((0,\infty)\) |
|---|---|
| Order of Continuity | \(C^{\infty}\) |
| Monotonic | ✔ |
| Monotonic Derivative | ✔ |
| Approximates Identity near the origin | ✖ |



