
According to Wikipedia,
Natural language processing is a sub-field of linguistics, computer science, and artificial intelligence concerned with the interactions between computers and human language, in particular how to program computers to process and analyze large amounts of natural language data.
We can divide the NLP process roughly into 2 parts
- Preprocessing
- Training
Preprocessing
The most important part of natural language processing is embedding means How to represent sentences? for example below is if we label every single character in a word but here is the problem. both words SILENT and LISTEN have the same letters.

So another approach, represent words with labels. As given below, I → 001 is fixed while training and testing.
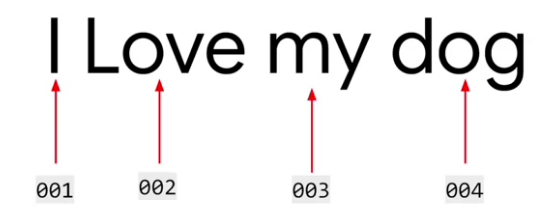
Encoding Sentences in Tensorflow / Keras
Let's import packages and libraries required.
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences # We will use it later
Now, let's take some sentences and tokenize them.
sentences = [
'I love my dog',
'I love my cat so much',
'You love my dog!'
]
# Create object of Tokenizer and tokenize sentences
tokenizer = Tokenizer(num_words = 100) # max distinct words first 100 words
tokenizer.fit_on_texts(sentences)
word_index = tokenizer.word_index # returns dictionary
print(word_index)
output
As you can see,
- Words are lower-cased
- ! mark removed
Creating Sequences from sentences
Now we need a sequence of codes for each sentence so that we can pass these sequences to Neural Networks.
We already created the Tokenizer instance and passed our sentences to its method tokenizer.fit_on_texts(sentences).
# Let's append new sentence to `sentences`
sentences.append("I love my Tom")
sequences = tokenizer.texts_to_sequences(sentences)
print(sequences)
output
But here we have another problem, What if the word is new to the dictionary? see last output, our dictionary doesn't have the word Tom and TensorFlow just ignored it. And always it does same, it ignores these words. But it is unfair and maybe we can add some wild/special value for unseen words.
Let's start again
# at Tokenizer instance creation add another keyword argument
# OOV means Out of vocabulary
tokenizer = Tokenizer(num_words=100, oov_token='<OOv>')
...... # do same as above
print(word_index)
print(sequence)
output
[[4, 2, 3, 5], [4, 2, 3, 6, 7, 8], [9, 2, 3, 5], [4, 2, 3, 1 ]]
As you can see, Tom is not in corpus and it is assigned as <'OOV'>. But as our dataset increases, the possibility of missing words reduces. or We can use GloVe or word2vec embeddings. We will see later.
Padding
But still here is a problem, as we know neural networks work only with fixed-size input. so we need to pad these sequences/trim to a fixed length.
Until now we got sequences from our sentences with different lengths of each sequence. Let's pad them to the same length.
padded_sequences = pad_sequences(sequences, padding='post',truncating='post',maxlen=5)
print(padded_sequences)
output
[4 2 3 6 7] last 'much' removed
[9 2 3 5 0 ]
[4 2 3 1 0 ]]
Training
We will create positive and negative review analysis systems from the IMDB dataset. For the setting thing, we need to install tensorflow-datasets or use google collab instead.
Once tensorflow-datasets installed, load IMDB Dataset.
import tensorflow_datasets as tfds
imdb, info = tfds.load('imdb_reviews', with_info=True, as_supervised=True)
This block will download the dataset if not found and store it in the most efficient format TFrecords.
Split data for Training and Testing. and convert in the appropriate format as we need in the above example → Separate sentences and labels
import numpy as np
train_data, test_data = imdb['train'], imdb['test']
training_sentences = []
training_labels = []
testing_sentences = []
testing_labels = []
for sentence, label in train_data:
training_sentences.append(str(sentence.numpy()))
training_labels.append(label.numpy())
for sentence, label in test_data:
testing_sentences.append(str(sentence.numpy()))
testing_labels.append(label.numpy())
print("Number of training samples: " + str(len(training_sentences)))
print("Number of testing samples: " + str(len(testing_sentences)))
output
Number of testing samples: 25000
Let's do some exploratory data analysis
# print 1st sentence and corrsponding label in traing data
print("Sentence: " + training_sentences[0])
print("Label: " +str(training_labels[0]))
output
Label: 0
Our training and testing data labels are in the list but for training, we need to convert them into NumPy array
training_labels_final = np.array(training_labels)
testing_labels_final = np.array(testing_labels)
## check by printing shapes
print("The shape of training labels: " + str(training_labels_final.shape))
print("The shape of testing labels: " + str(testing_labels_final.shape))
output
The shape of testing labels: (25000,)
Preprocessing as we did above
We need to preprocess data as we did above. Code is the same as above.
## define params so that we can change easily
vocab_size = 100000
embedding_dim = 16
max_length = 120
trunc_type = 'post'
pad_type = 'post'
oov_tok = "<OOV>"
tokenizer = Tokenizer(num_words=vocab_size, oov_token=oov_tok)
tokenizer.fit_on_texts(training_sentences)
word_index = tokenizer.word_index
training_sequences = tokenizer.texts_to_sequences(traing_sentences)
training_padded = pad_sequences(trainining_sequences, maxlen= max_length, padding=pad_type, truncating=trunc_type)
testing_sequences = tokenizer.texts_to_sequences(testing_sentences)
testing_padded = pad_sequences(testing_sequences, maxlen=max_length, padding=pad_type, truncating=trunc_type)
Let's check our training data and testing data shape
print("Training Input: " + str(training_sequences.shape))
print("Testing Input: " + str(testing_sequences.shape))
output
Testing Input: (25000, 120)
Create Model in Keras
Keras provides a higher-level API for TensorFlow so it is too easy to create and train neural networks.
model = tf.keras.Sequential([
tf.keras.layers.Embedding(vocab_size, embedding_dim, input_length=max_length),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(6,activation='relu'),
tf.keras.layers.Dense(1, activation='sigmoid')
])
print(model.summary())
output
Model: "sequential" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= embedding (Embedding) (None, 120, 16) 1600000 _________________________________________________________________ flatten (Flatten) (None, 1920) 0 _________________________________________________________________ dense (Dense) (None, 6) 11526 _________________________________________________________________ dense_1 (Dense) (None, 1) 7 ================================================================= Total params: 1,611,533 Trainable params: 1,611,533 Non-trainable params: 0 _________________________________________________________________
Compile and Start Training
## Compile Model
model.compile(optimizer='rmsprop',
loss='binary_crossentropy',
metrics=['accuracy'])
num_epochs = 10
history = model.fit(training_padded,
training_labels_final,
epochs=num_epochs,
validation_data=(testing_padded, testing_labels_final))
output
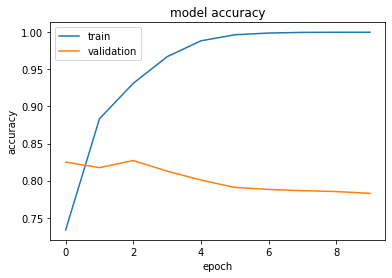
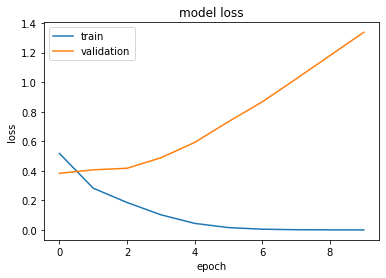
Epoch 1/10 782/782 [==============================] - 8s 10ms/step - loss: 0.5179 - accuracy: 0.7336 - val_loss: 0.3833 - val_accuracy: 0.8250 Epoch 2/10 782/782 [==============================] - 8s 10ms/step - loss: 0.2824 - accuracy: 0.8834 - ... Epoch 10/10 782/782 [==============================] - 8s 10ms/step - loss: 2.0107e-04 - accuracy: 0.9999 - val_loss: 1.3380 - val_accuracy: 0.7828
Let's Visualise training-validation loss-accuracy
import matplotlib.pyplot as plt
# accuracy
plt.plot(history.history['accuracy'])
plt.plot(history.history['val_accuracy'])
plt.title('model accuracy')
plt.ylabel('accuracy')
plt.xlabel('epoch')
plt.legend(['train', 'validation'], loc='upper left')
plt.show()
# "Loss"
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.title('model loss')
plt.ylabel('loss')
plt.xlabel('epoch')
plt.legend(['train', 'validation'], loc='upper left')
plt.show()
output
What is embedding
tf.keras.layers.embedding turns positive integers (We encoded in preprocessing stage) into dense vectors of fixed size. This layer can only be used as the first layer in a model
We will learn about embedding in detail here until now let's visualize embedding in Tensorflow embedding projector
Find reverse map index → Word
# Reverse map from index to word
inv_map = {v: k for k, v in word_index.items()}
Now get weights of the embedding layer i.e. first layer. Its shape must be vocab_size x embedding_dim
e = model.layers[0]
weights = e.get_weights()[0]
print(weights.shape)
output
Now download these weights and words in the .tsv file. Then go to the Tensorflow embedding projector and visualize.
import io
out_v = io.open('vecs.tsv', 'w', encoding='utf-8')
out_m = io.open('meta.tsv', 'w', encoding='utf-8')
vocab_size = len(inv_map.keys())
for word_num in range(1, vocab_size):
word = inv_map[word_num]
embeddings = weights[word_num]
out_m.write(word + '\n')
out_v.write('\t'.join([str(x) for x in embeddings]) + '\n')
out_v.close()
out_m.close()
References and Code
[1] Natural Language Processing in Tensorflow by Laurence Moroney
