According to Wikipedia,
CUDA is a parallel computing platform and application programming interface model created by Nvidia. It allows software developers and software engineers to use a CUDA-enabled graphics processing unit for general purpose processing – an approach termed GPGPU.
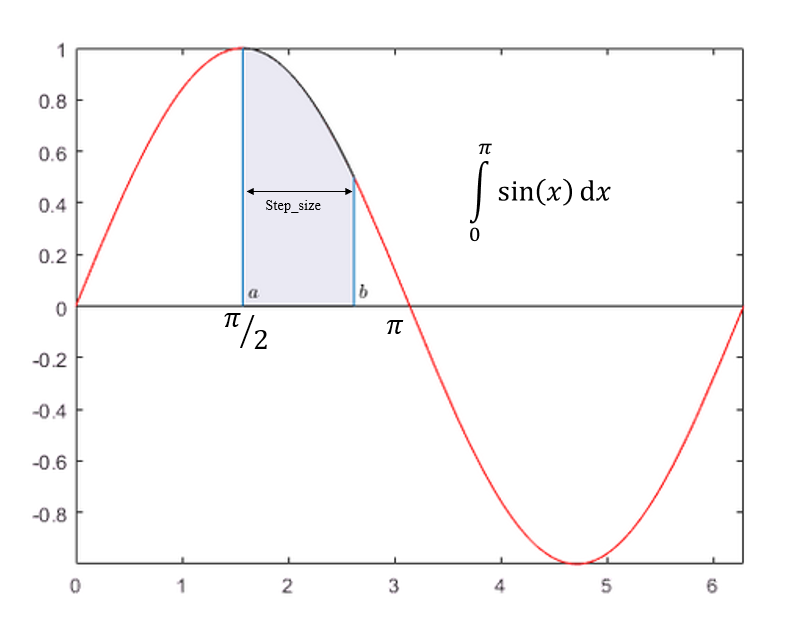
How to find the area under a function?
We are taking N i.e no of steps from 0 -> π. In each step, we will find the middle point of the strip shown in the above image. and find the area of that single strip with the following formula.

Basics of Cuda c
Nvidia GPU is called a Device and the CPU from where code is invoked is called the host. for running code on the device, we need to transport/copy our data/variables to GPU Memory.

How to Send data back and forth?
for sending data/variables back and forth, we will use Cuda API calls. Allocate space on GPU Memory as follow,
cudaError_t cudaMalloc ( void ** devPtr, size_t size )copy data either from host to device (CPU → GPU) or device to host (GPU → CPU). That flow is dependent on the fourth parameter cudaMemcpyKind kind
__host__ cudaError_t cudaMemcpy ( void* dst,
const void* src,
size_t count,
cudaMemcpyKind kind )Code
// declare pointer of type float
float *d_a;
// allocate memory on GPU
cudaMalloc(&d_a,sizeof(float) * N);
// Now we will copy data from CPU pointed by 'a' to GPU
// For copying from->to
// host->device === cudaMemcpyHostToDevice
// Device->Host === cudaMemcpyDeviceToHost
cudaMemcpy(a,d_a,sizeof(float) * N,cudaMemcpyDeviceToHost);
// Free memory on GPU
cudaFree(d_a);How to run code on GPU?
__global__ function will be executed on GPU Device and can be called as
functionName<<<block, ThreadPerBlock>>>();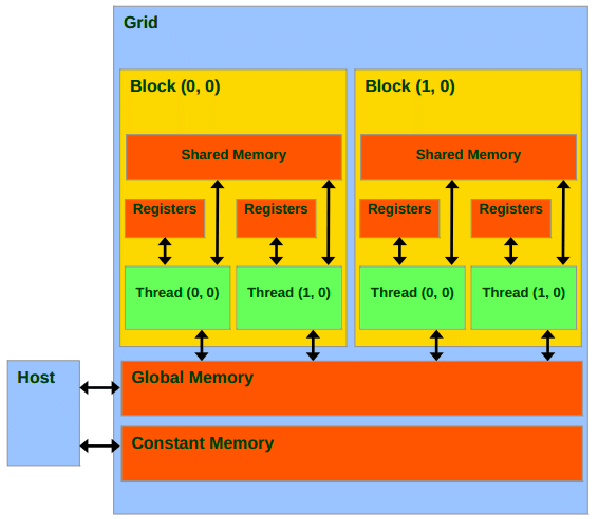
__global__ void kernel(args) {
// I can't return anything SORRY
// I will execute on GPU
// When you call kernel<<<block,threads>>>(); on host
}How to find the area of a sine wave?
We are taking N i.e no of steps 1000000. for each step, GPU computes the area of strip and saves it in the array on GPU memory. after all operations are completed this array is copied to Host i.e. CPU memory Aka RAM. Then all array values are added to the final output. output must be 2 but some minute error, it will be around 1.999.
#include<cuda_runtime.h>
#include<stdio.h>
#include<cuda_profiler_api.h>
#include<stdlib.h>
#define N 1000000
__global__ void vector_add(float *a, int n) {
float step_size = (float)22/(7*N);
for(long int i = blockIdx.x * blockDim.x + threadIdx.x;
i < n;
i = i + 800){ // 800 is 100*8 i.e. blocks*threads_per_block
// blockIdx.x - block id
// blockDim.x - size of block or threads in block
// threadIdx.x - thread id in block
a[i] = step_size * sinf(i * step_size + (step_size / 2));
}
}
float add(float *a){
float ad = 0.0;
for(long int i = 0; i < N; i++)
ad += *(a+i);
return ad;
}
int main(){
float *a;
float *d_a;
// Allocate memory in RAM
a = (float*)malloc(sizeof(float) * N);
// allocate memory on GPU i.e.Device
cudaMalloc(&d_a, sizeof(float) * N);
// call kernel with 100 blocks and 8 threads per block
vector_add<<<100,8>>>(d_a, N);
// copy data from device to host i.e. GPU to CPU
cudaMemcpy(a,d_a,sizeof(float) * N, cudaMemcpyDeviceToHost);
printf("%f", add(a));
// Free memory
free(a);
cudaFree(d_a);
return 0;
}How to run code and get output?
check that your PC/laptop has Nvidia graphic card and whether it is supporting Cuda. if yes, install Cuda on your machine. Then save the above code as main.cu and in the same directory run commands
for compiling,
nvcc main.cufor running,
./a.outfor profiling,
nvprof ./a.out