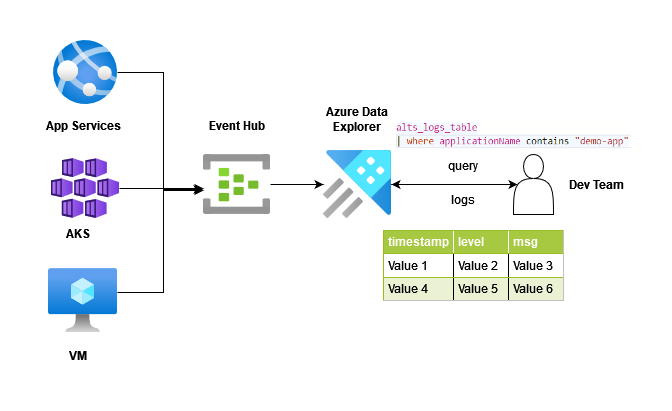
Storing and managing logs is one of the important activities in software companies. Because using logs you can find root causes of multiple things like bugs, downtime, cyber attack, etc. Different cloud providers have their own managed logging and monitoring systems like AWS have cloud-watch, cloud-trail, etc and Azure has application insight. But suppose you have hundreds of microservices inside the Kubernetes cluster and you want easy to use, easy to set up logging system which will work exactly the same for all micro-services. You can use fluentd but in this article, I will show you how to use Event hub and Azure Data Explorer to collect and access logs in Azure.
As you can see in the feature image, your application which can be deployed in whether app service, Azure Kubernetes Service, or Virtual Machine will push logs to the Event hub and then Azure data explorer will do storing and querying job for you. In this article, I will run my simple flask application locally and it will push logs to the event hub which we access using azure data explorer.
Plan of action,
- Create infrastructure using terraform
- Writing a small flask web app
- checking logs in ADX
You can find all code used in this article at https://github.com/lets-learn-it/terraform-learning/tree/azure/06-eh-adx-logging
Creating Infrastructure
I am using terraform version Terraform v1.0.11 Add Azure provider and make sure to use the version of azurem > "2.88.1" because we are using $Default in azurerm_kusto_eventhub_data_connection
terraform {
required_providers {
azurerm = {
source = "hashicorp/azurerm"
version = "2.88.1"
}
}
}
provider "azurerm" {
features {}
}Now create one resource group in which all our resources will reside. Like below
resource "azurerm_resource_group" "logs_rg" {
name = var.resource_group
location = "East US"
}Now create an event hub namespace and event hub in that namespace. We will use the default consumer group for this example.
resource "azurerm_eventhub_namespace" "eh_namespace" {
name = var.eh_namespace
location = azurerm_resource_group.logs_rg.location
resource_group_name = azurerm_resource_group.logs_rg.name
sku = "Standard"
capacity = 1
zone_redundant = true
tags = var.tags
}
resource "azurerm_eventhub" "eh" {
name = var.eh_name
namespace_name = azurerm_eventhub_namespace.eh_namespace.name
resource_group_name = var.resource_group
partition_count = 1
message_retention = 1
}
data "azurerm_eventhub_consumer_group" "default" {
name = "$Default"
namespace_name = azurerm_eventhub_namespace.eh_namespace.name
eventhub_name = azurerm_eventhub.eh.name
resource_group_name = var.resource_group
}We need an Azure data explorer cluster and database in it to store all logs.
resource "azurerm_kusto_cluster" "adx" {
name = var.adx_cluster
location = azurerm_resource_group.logs_rg.location
resource_group_name = azurerm_resource_group.logs_rg.name
engine = "V3"
double_encryption_enabled = var.double_encryption
sku {
name = var.adx_sku_name
capacity = var.adx_sku_capacity
}
tags = var.tags
}
resource "azurerm_kusto_database" "database" {
name = var.adx_database
resource_group_name = var.resource_group
location = azurerm_resource_group.logs_rg.location
cluster_name = azurerm_kusto_cluster.adx.name
hot_cache_period = var.hot_cache_period
soft_delete_period = var.soft_delete_period
}Create variable find and add all variables we are using till now.
variable "resource_group" {
description = "where we place event hub and azure data explorer"
type = string
}
variable "adx_cluster" {
description = "name of adx cluster"
type = string
}
variable "adx_database" {
type = string
description = "name of adx dataset"
}
variable "eh_namespace" {
type = string
description = "name of event hub namespace"
}
variable "eh_name" {
type = string
description = "name of event hub"
}
variable "double_encryption" {
type = bool
}
variable "hot_cache_period" {
type = string
description = "data will be cached for this no of days"
}
variable "soft_delete_period" {
type = string
description = "after these no of days data will be deleted"
}
variable "adx_sku_name" {
type = string
description = "type of adx cluster"
}
variable "adx_sku_capacity" {
type = string
}
variable "tags" {
type = map(string)
}
variable "adx_eh_connection_name" {
type = string
}
variable "adx_db_table_name" {
type = string
}
variable "ingestion_mapping_rule_name" {
type = string
}
variable "eh_message_format" {
type = string
default = "JSON"
}create terraform.tfvars file for providing values to all variables used,
resource_group = "eh-adx-logs"
adx_cluster = "logscluster"
adx_database = "logsdb"
double_encryption = true
hot_cache_period = "P31D"
soft_delete_period = "P365D"
adx_sku_name = "Standard_D11_v2"
adx_sku_capacity = 2
eh_namespace = "logseventhubns"
eh_name = "logs_eventhub"
adx_eh_connection_name = "adxehconn"
adx_db_table_name = "logs_table"
ingestion_mapping_rule_name = "logs_table_json_ingestion_mapping"
tags = {
"environment": "prod"
}To create these resources run a plan and apply. You will see, terraform is creating 5 resources. (Azure data cluster took 15 min for me 😒)
terraform plan
# then run
terraform applyCurrently, terraform does not support creating tables in the database and mapping for tables so we will create it manually.
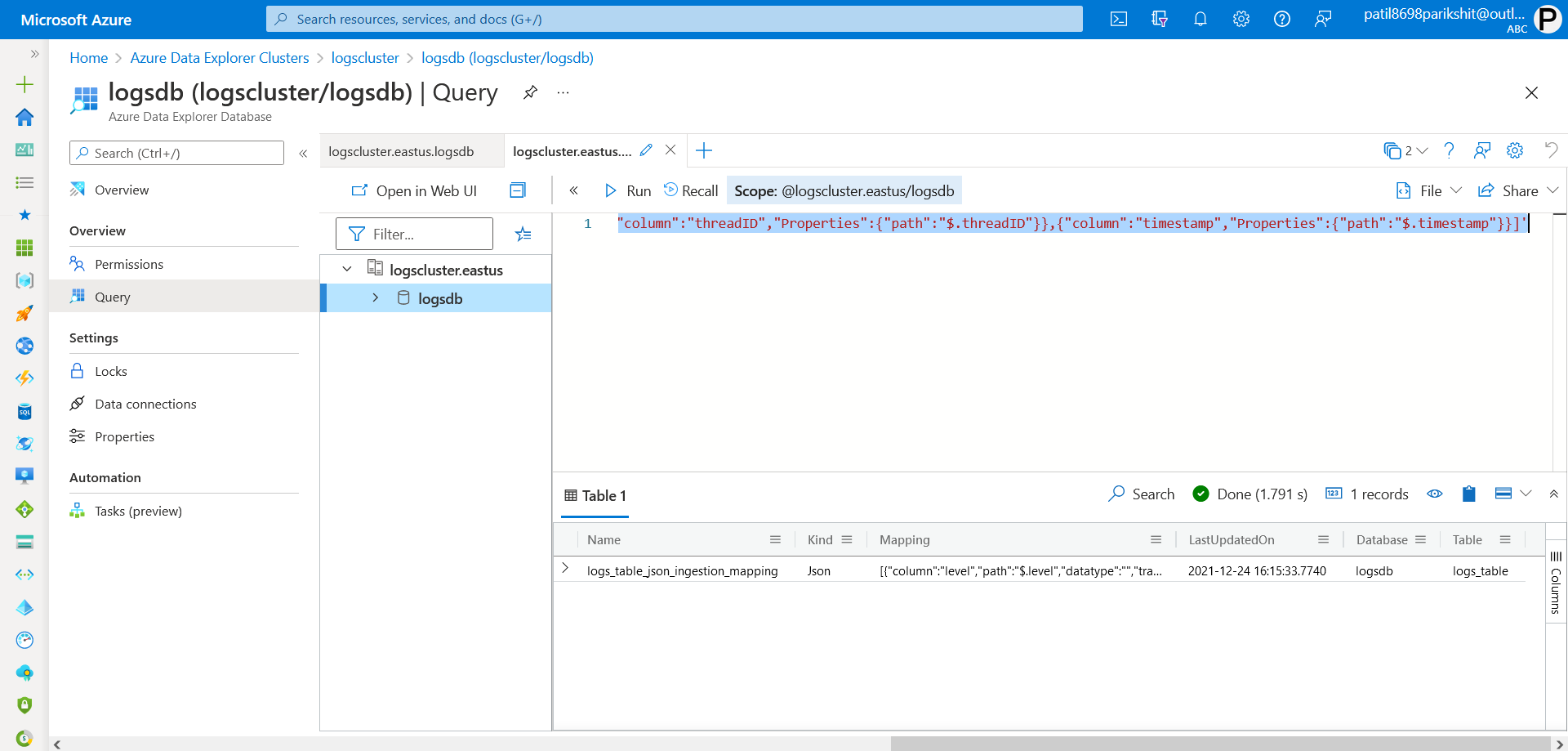
To open query editor, go to Azure data explorer cluster in Azure dashboard, and on the left side, you can find databases. In databases, you can find our database, logsdb. double click on it then select Query. In that run following table creation query.
.create table logs_table (
level:string,
message:string,
loggerName:string,
exception:string,
applicationName:string,
processName:string,
processID:string,
threadName:string,
threadID:string,
timestamp:datetime
)To create ingestion mapping, run the following query
.create table logs_table ingestion json mapping 'logs_table_json_ingestion_mapping'
'[{"column":"level","Properties":{"path":"$.level"}},{"column":"message","Properties":{"path":"$.message"}},{"column":"loggerName","Properties":{"path":"$.loggerName"}},{"column":"exception","Properties":{"path":"$.exception"}},{"column":"applicationName","Properties":{"path":"$.applicationName"}},{"column":"processName","Properties":{"path":"$.processName"}},{"column":"processID","Properties":{"path":"$.processID"}},{"column":"threadName","Properties":{"path":"$.threadName"}},{"column":"threadID","Properties":{"path":"$.threadID"}},{"column":"timestamp","Properties":{"path":"$.timestamp"}}]'After creating the table and mapping, we need to create a connection between the event hub and the azure data explorer. While creating infrastructure using terraform, we didn't create it because it need a table and mapping. Now add the following resources in Terraform and run the plan and apply again.
resource "azurerm_kusto_eventhub_data_connection" "eventhub_connection" {
name = var.adx_eh_connection_name
resource_group_name = var.resource_group
location = azurerm_resource_group.logs_rg.location
cluster_name = azurerm_kusto_cluster.adx.name
database_name = azurerm_kusto_database.database.name
eventhub_id = azurerm_eventhub.eh.id
consumer_group = data.azurerm_eventhub_consumer_group.default.name
table_name = var.adx_db_table_name
mapping_rule_name = var.ingestion_mapping_rule_name
data_format = var.eh_message_format
}Flask Application
To push logs to the event hub, we need EventhubHandler for python logging library. Install it using pip as follow
pip install EventhubHandlerNow, import required packages and create a logger. Make sure to use JSONFormatter it because our mapping is expecting JSON from the event hub. I am creating a root level logger so that all logs in all modules will go to the event hub.
from flask import Flask
import logging
from EventhubHandler.handler import EventHubHandler
from EventhubHandler.formatter import JSONFormatter
app = Flask(__name__)
logger = logging.getLogger()
eh = EventHubHandler()
eh.setLevel(logging.DEBUG)
# format will be depends on what you choose at adx
# I am using JSON
formatter = JSONFormatter({"level": "levelname",
"message": "message",
"loggerName": "name",
"processName": "processName",
"processID": "process",
"threadName": "threadName",
"threadID": "thread",
"timestamp": "asctime",
"exception": "exc_info",
"applicationName": ""})
eh.setFormatter(formatter)
logger.addHandler(eh)Write some endpoints so that we can test our flask application. I created /exception endpoint to check how exceptions are getting logged.
@app.route("/")
def hello_world():
logger.info("inside hello world")
return "<p>Hello, World!</p>"
@app.get("/exception")
def exception():
try:
x = 1 / 0
except ZeroDivisionError as e:
logger.exception('ZeroDivisionError: {0}'.format(e))
return "Exception Occured"
if __name__ == '__main__':
app.run(host="0.0.0.0")Save all flask code in one file & name it main.py. And make sure to set 3 environment variables as follow (for Linux based system),
export applicationName="my-log-app"
export eh_ns_connection_string=<event hub namespace connection string>
export eventhub_name="logs_eventhub"
Run application using the following command,
python main.pyChecking logs
To check logs, we need to run query in that same query editor. We set applicationName=my-log-app. Now using this we will get last 20 min logs
logs_table
| where applicationName contains "my-log-app"
| where timestamp > ago(20m)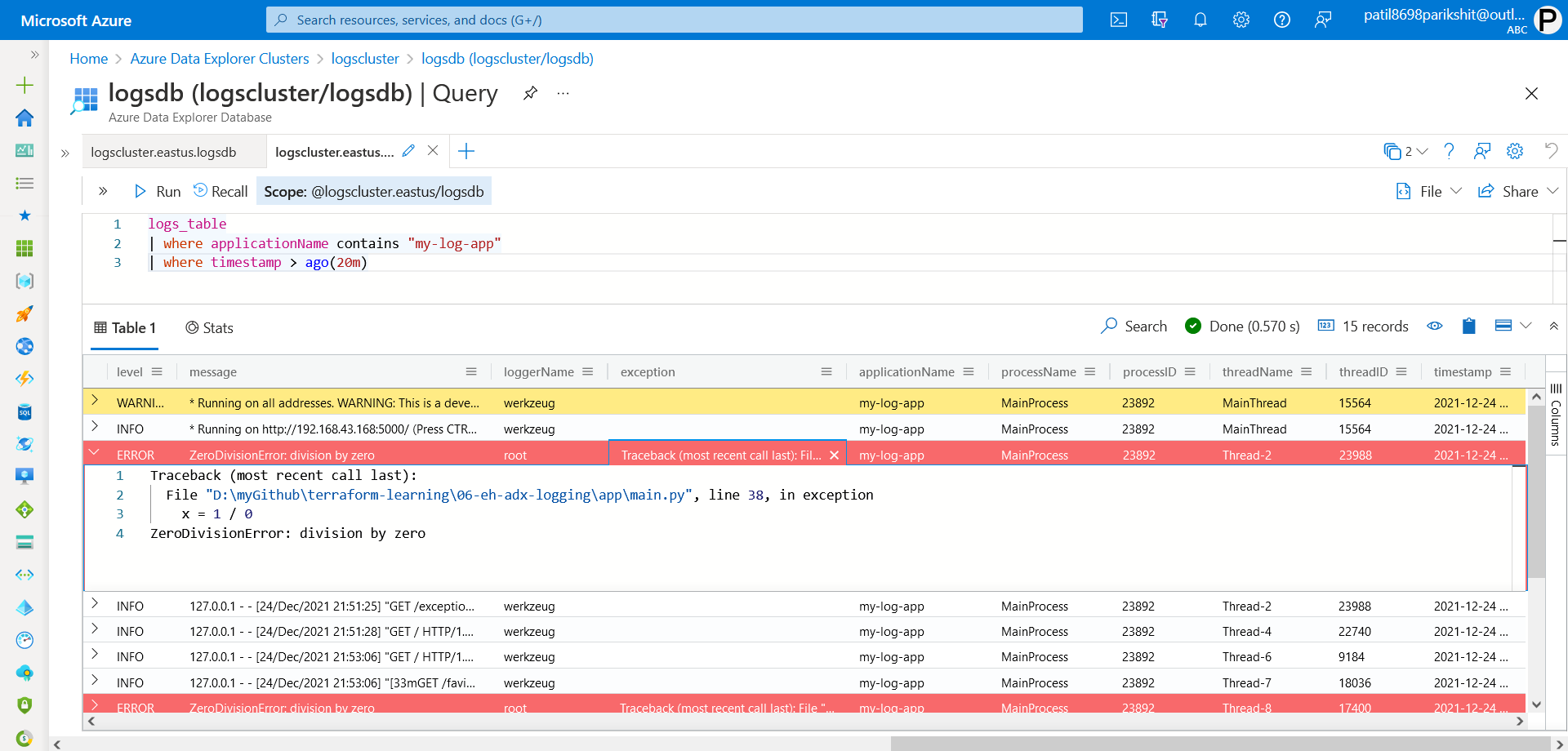
When to use & when not
- If you have 100s of microservices then only. My team is using this and we have 40 microservices. The surprising thing is we have never gone above 10% Azure data cluster utilization.
- If you have fewer services then it will be too costly per service. check pricing https://azure.microsoft.com/en-in/pricing/details/data-explorer/#pricing