If you are ready to read a lot of web pages then please go to apache Kafka documentation because that will make sense And if you are comfortable watching video lectures then watching learn-apache-Kafka-for-beginners instead of reading this blog will be cool. But if you want to know what is apache Kafka quickly, then stay with me.
Kafka is a pub-sub distributed system consisting of servers and clients that communicate via a high-performance TCP network protocol. You can write a lot of messages/events to Kafka and read those at your convenience.
Terminologies
Producers & Consumers
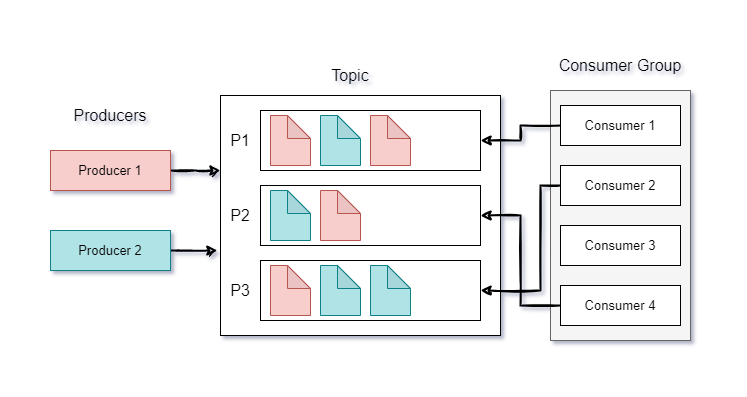
producers/publishers are clients who write data/events to Kafka, while consumers/subscribers are clients who read data/events from Kafka. Both consumers and producers may or may not have knowledge of each other's existence. Both are fully decoupled.
When producers write data to Kafka topic, that data is assigned to partitions randomly unless the key is provided. All events with the same key will be assigned to the same partition.
Brokers
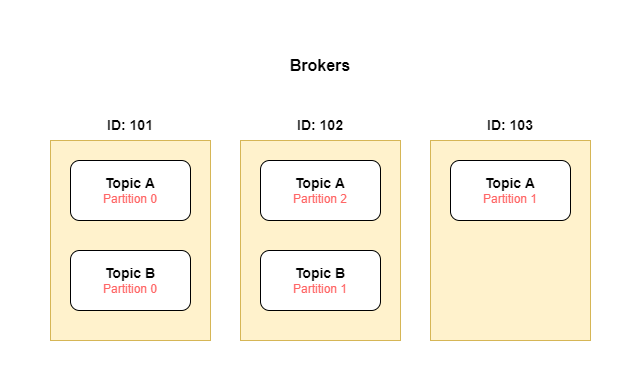
Brokers are machines on which apache Kafka is running and providing its services both to producers and consumers. The system can have multiple brokers (and that is recommended for high availability and fault tolerance) and each broker can be identified by id. Each broker can have one or more topic partitions and those partitions will be replicated across multiple brokers.
If the client connects to any broker (called a bootstrap broker), the client will be connected to the entire cluster.
Topics, Partitions & Offsets
Topics are like tables in a database or virtual hosts in Rabbit MQ. Events are organized and durably stored in topics. Topics can have multiple producers writing events and at the same time, multiple consumers are consuming those events.
Topics are split into partitions like 0,1, 2, 3, ... etc And each message within the partition gets an incremental id called offset. And these offsets have meaning only in that specific partition.
Each topic has a replication factor that states how many times every partition in the topic should be replicated across different brokers. And it should be > 1. If one broker goes down, another broker serves data.
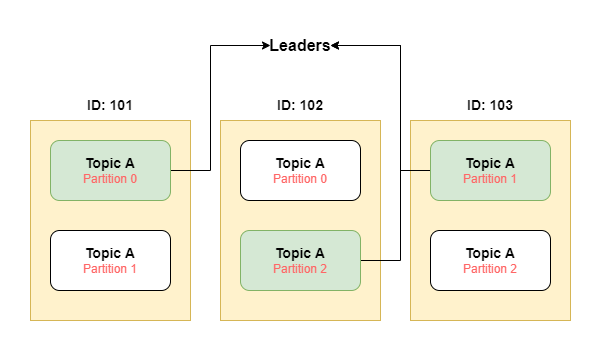
As each partition is replicated across brokers, then who will be the owner of that partition? Here comes the leader for partition, at any time only ONE broker can be the leader for a given partition. Only that leader can receive and serve data for that partition and other brokers will synchronize data.
Suppose in the below image broker with id 101 goes down, then also partition 0 of topic A is already present on the broker with id 102. So broker with id 102 will be the new leader for the partition 0.
Once data is written to a partition, it can't be changed (immutability)
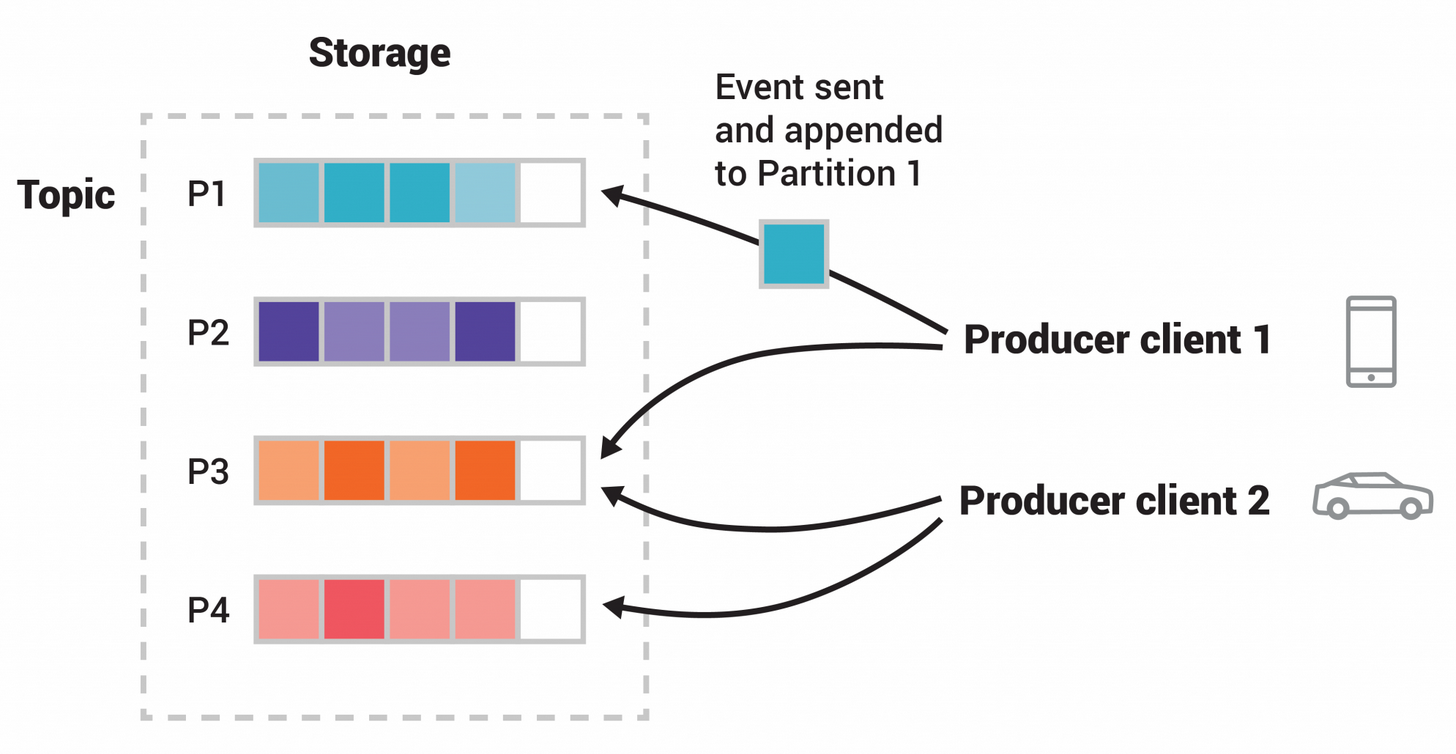
As you can see in the above image, there is a topic that has 4 partitions.
Producers and Message Keys
Producers write data to topics (which are made of partitions). Producers automatically know to which broker & partition to write and in case of broker failure, producers will automatically recover.
Producers can choose to receive acknowledgment of data writes. default is acks=1
- acks=0: no ack (possible data loss)
- acks=1: ack from leader only (limited loss)
- acks=2: leader + replicas (no data loss)
Message Keys
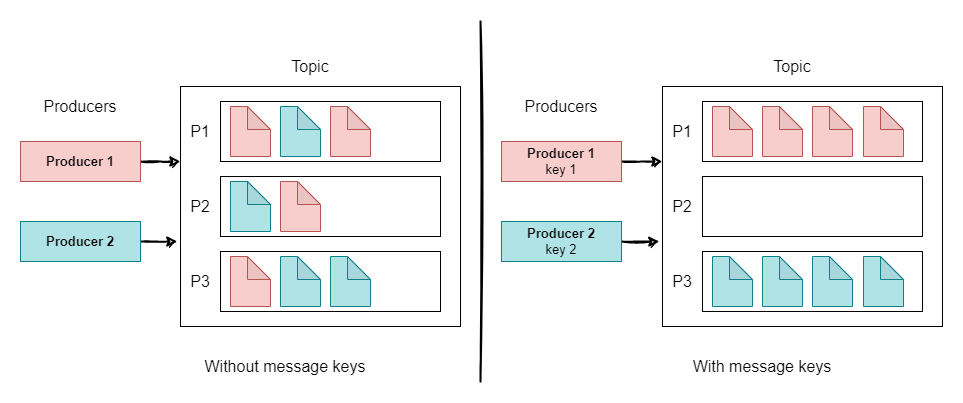
Producers can send keys with messages (string, number, etc). When the key is null and the default partitioner is used, the record will be sent to one of the available partitions of the topic at random. A round-robin algorithm will be used to balance the messages among the partitions.
if the key is sent then all messages with the same key will go to the same partition.
Consumers and Consumer Groups
Consumers read data from the topic (identified by name). Consumers know which broker (leader) to read from and if a broker fails, how to recover. Data is read in order within each partition. The same message can be read multiple times if the consumer wants to.
Consumer Groups
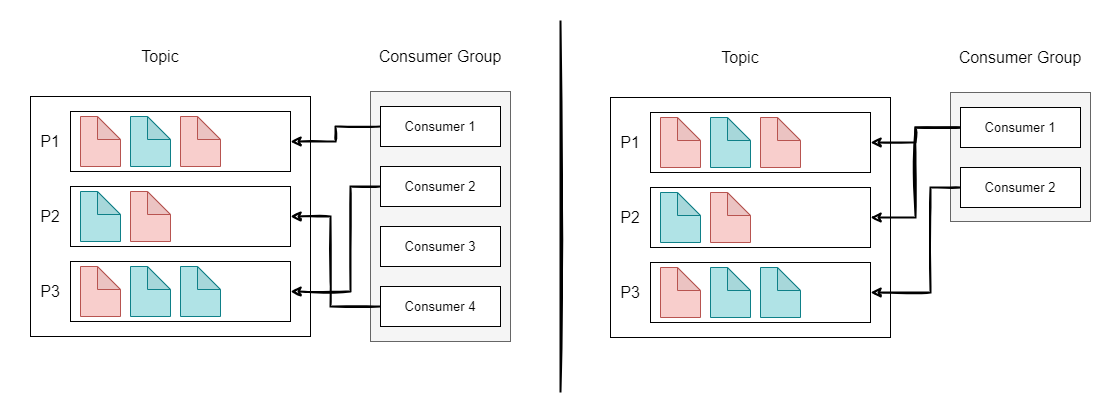
Consumers can read data in consumer groups. Each consumer within the group reads from exclusive partitions. if the group has more consumers than partitions, then some consumers will be inactive and if the group has fewer consumers than partitions, then some consumers will read from multiple partitions.
Consumer Offset
Kafka stores the offsets at which a consumer group has been reading. It tells the consumer where it was the last time in the partition. & which is the next message to read? Offsets are committed live in a Kafka topic __consume_offsets.
When the consumer in the group has processed data received from Kafka, it should be committing the offsets. If consumers die, it will be able to read back from where it left off (thanks to committed consumer offsets).
Apache Kafka Guarantees
- Messages are appended to a topic partition in the order they are sent
- Consumers read messages in order stored in the topic partition.
- With a replication factor of N, producer & consumer can tolerate up to N-1 brokers being down.
- As long as the number of partitions remains constant for a topic (no new partitions), the message with the same key will always go to the same partition.
